
•
Published

A technical tour of trusted execution environments for AI, why the hardware finally caught up, and how to build systems where privacy is something you can verify.
The best data never reaches the model
The data that would benefit most from AI is exactly the data people are least willing to send to someone else's GPU.
Your full medical history could make a model's diagnostic suggestions dramatically better. Your complete financial picture would make an AI advisor actually useful. And the same goes for private messages, genomes, and therapy notes: the more intimate the data, the more value a capable model can extract from it, and the more catastrophic it feels to upload it to a third party.
Today, the industry's answer to this tension is a privacy policy, claiming “we don’t train on your data,” or “we delete your logs after 30 days,” and that “your conversations are private.” These may all be true. But a policy is a promise, and a promise is not a security model.
There is a better answer, and the hardware to deploy it at scale shipped recently enough that most people building AI products haven't internalized it yet. This post is about that answer: running AI inference inside trusted execution environments (TEEs), where privacy is enforced by the processor and where you can prove it.
From "trust us" to "verify us"
A TEE, sometimes called an enclave or confidential computing, gives you two properties that a privacy policy cannot:
Confidentiality. The code and data inside the enclave are encrypted in memory. Nobody outside can read them. Not the cloud provider, the machine's administrator, someone with a debugger attached to the host, or someone who walks out of the datacenter with the DRAM.
Attestation. The hardware measures exactly which code is running inside the enclave and signs that measurement with a key fused into the silicon at manufacturing. Anyone can check this signature against the chip vendor's public keys. This is the part people underrate. Confidentiality tells you nobody can peek. Attestation tells you precisely what program your data was handed to, and that claim is backed by cryptography rather than by a vendor's word.
Put together: you can send your data to a machine you've never seen, operated by a company you don't trust, and receive a hardware-signed proof that a specific, known piece of software processed it inside an encrypted boundary and that nothing else could observe it.
This changes the answer to the question "who can I trust with my data?" Today the answer is a reputation ranking: a handful of large labs and hyperscalers whose brands are the product's security model. Attestation replaces the brand with a proof. A small startup, an academic lab, or an open-weight model served by an operator you've never heard of can offer exactly the same guarantee as the biggest names, because the guarantee comes from the silicon and the published code, not from the letterhead.
A short primer, in case TEEs are new to you
Feel free to skip this section if you've worked with enclaves before.
A TEE is a hardware-isolated region of a processor. The memory controller encrypts everything the enclave writes to RAM, with keys that never leave the chip. The host operating system and hypervisor can schedule the enclave and allocate resources to it, but they see only ciphertext. Modern implementations you'll encounter are Intel TDX and AMD SEV-SNP on the CPU side, which protect entire virtual machines, and NVIDIA Confidential Computing on the GPU side, which extends the same guarantees to accelerator memory.
Attestation works roughly like this. At boot, the hardware computes a hash (the "measurement") of everything loaded into the enclave: firmware, kernel, application code. When a client connects, it sends a random nonce. The enclave asks the hardware to produce a quote: a signed statement containing the measurement, the nonce, and typically a public key that was generated inside the enclave. The signature chains back to the chip manufacturer. The client checks the chain, checks the nonce (to prevent replay), checks the measurement against the value it expects, and only then starts talking, encrypting traffic to the key from the quote.
What attestation proves: this exact code, on genuine hardware, with these security settings, holds this key, what it does not prove: that the code is good. An enclave running malicious code will attest beautifully to running malicious code. This gap matters, and it's where the trust loop comes in later.
Three Tiers of Trust
There are three tiers of trust assumptions being sold today:
Tier 1: policy-based privacy. "We don't store your prompts." This describes most AI APIs, including some that market themselves specifically on privacy. Venice.ai is an instructive example because they were unusually candid about it: in their own 2025 write-up of their architecture, they explained that prompts were anonymized through a proxy and never stored server-side, but were processed in plaintext on a decentralized GPU network, and that anyone with access to those GPUs could, in principle, read them. Anonymization plus retention policy, with no way for a user to verify any of it. To their credit, they said so plainly, and to their further credit, they have since added a hardware-attested mode. The trajectory is the interesting part: even privacy-first companies end up at attestation once users start asking "prove it."
Tier 2: operator-rooted attestation. AWS Nitro Enclaves is the canonical example. Nitro gives real isolation: the enclave is carved out of an EC2 instance, has no network, no persistent storage, and communicates only over a local socket. It issues attestation documents. But those documents are signed by AWS's own certificate authority, and the isolation is enforced by AWS's hypervisor. The root of trust is the operator. If your threat model includes the cloud provider, Nitro does not remove them from it; AWS remains inside the trusted computing base. This is a meaningful step up from a policy, and for many workloads it's enough. It is not the same claim as tier 3, and the two get conflated constantly. Nitro Enclaves also cannot attach GPUs at all as of this writing, which makes the point somewhat academic for AI inference.
Tier 3: silicon-rooted attestation. Intel TDX, AMD SEV-SNP, and NVIDIA Confidential Computing. The measurement is signed by keys burned into the processor by the manufacturer. The cloud provider, the hypervisor, and the datacenter operator are all outside the trusted computing base. Google can run the machine and still be unable to read your data or forge the proof. Your residual trust lands on the chip vendors themselves: their silicon, their microcode, their resistance to side-channel attacks. That is not zero trust, and anyone who tells you otherwise is selling something. But it is a radically smaller and better-understood trust surface than "the operator and everyone they employ."
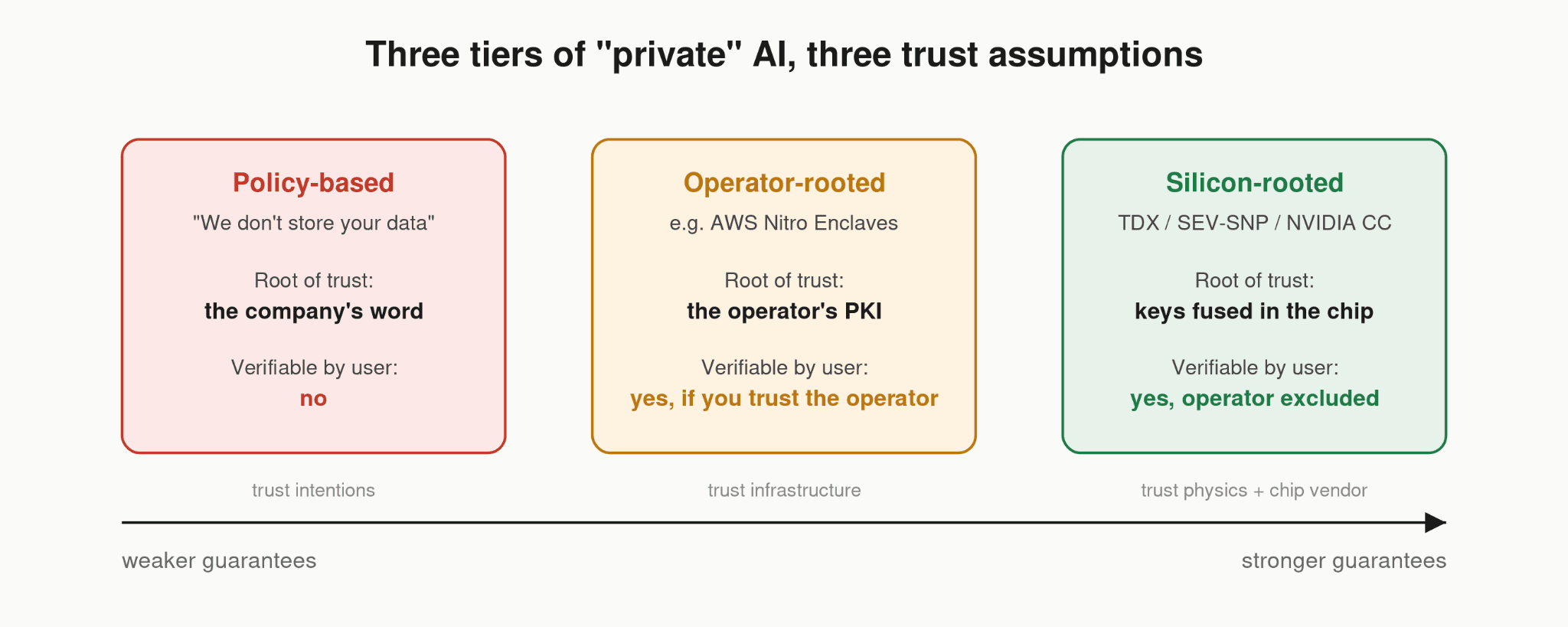
The one-line summary: tier 1 you trust a company's intentions, tier 2 you trust a company's infrastructure, tier 3 you trust the laws of physics plus Intel, AMD, and NVIDIA.
Why now: the hardware finally caught up
Confidential computing on CPUs has existed for years. The reason it's suddenly relevant to AI is that GPUs joined the party, and then the clouds turned it into a product page.
NVIDIA's Hopper generation (H100, H200) shipped the first production GPU TEE. In confidential mode, GPU memory is protected, and data crosses the PCIe bus through encrypted bounce buffers coordinated with the CPU's TEE. It works, with a real but modest performance tax on I/O-heavy workloads.
Blackwell is where it tips. It is the first GPU with TEE-I/O: encryption is inline on the interconnect, including NVLink between GPUs, and NVIDIA reports near-identical throughput with confidential mode on versus off. Multi-GPU confidential inference of frontier-scale models stops being a research demo and becomes a checkbox.
On the cloud side, as of mid-2026:
Provider | Confidential CPU | Confidential GPU | Notes |
|---|---|---|---|
Azure | SEV-SNP, TDX | H100 (GA since 2024) | First to ship confidential GPUs |
Google Cloud | SEV-SNP, TDX | H100 (GA), Blackwell RTX PRO 6000 (preview) | Confidential GKE nodes autoscale |
AWS | SEV-SNP (limited regions) | None | Nitro Enclaves: no GPU support |
The practical upshot: you can today run an autoscaling Kubernetes cluster of confidential H100 nodes on GCP, attested down to the silicon, with spot pricing. Two years ago, this existed mostly in papers.
Apple, meanwhile, made the same architectural bet for consumers: Private Cloud Compute runs Apple Intelligence on custom silicon enclaves with publicly auditable software images.
Closing the trust loop
Attestation proves what code ran. It does not prove the code was worth running. A complete architecture has to close the loop from source code all the way to the end user's device. Here is the chain we consider the reference design:
The code is knowable. Either the enclave application is open source, or (more on this below) its critical properties are provable.
The build is reproducible. Anyone can compile the published source and arrive at the same measurement, bit for bit. Without this, "open source" is decorative: you'd be trusting that the published code corresponds to the deployed binary.
The measurement is published somewhere immutable. A transparency log, or a blockchain. At Self, we publish the hash of the code running inside our enclaves on-chain. A blockchain happens to be a good fit here: an immutable, timestamped, publicly watchable record is exactly what a measurement registry should be, and it lets anyone detect if we ever silently swap the code.
Keys live and die inside the enclave. The key pair that decrypts user traffic and signs responses is generated inside the TEE and never leaves it. The attestation quote binds this public key to the measurement. Compromise the host, and you still get nothing.
The client verifies. This is the step most deployments skip, and skipping it voids everything above. If verification happens on the operator's server, you're back to trusting the operator. The check belongs in the mobile app or the browser, on the user's side of the trust boundary.

In pseudocode, the client side of the loop looks like this:
# Client-side verification, vendor-neutral sketch
nonce = random_bytes(32)
quote = enclave.get_attestation(nonce)
# 1. Signature chains to the chip vendor's root keys
verify_cert_chain(quote, roots=[INTEL_ROOT, AMD_ROOT, NVIDIA_ROOT])
# 2. Freshness: this quote was made for us, now
assert quote.nonce == nonce
# 3. The code is the code we expect
expected = fetch_measurement_from_transparency_log() # or on-chain
assert quote.measurement == expected
# 4. Security config is sane (debug off, up-to-date TCB)
assert not quote.flags.debug_enabled
assert quote.tcb_status == "UpToDate"
# 5. Pin the enclave's key and encrypt everything to it
session = establish_channel(quote.enclave_public_key)
That’s five checks, and skipping any of them undermines the other four
The verifiability dividend
Once inference outputs are signed by a key that attestation has bound to known code, a model's answer becomes a portable fact. Anyone, anywhere, later, can verify that this output came from this model processing some input inside this code, without trusting the operator. That's a new primitive, opening the door for more compounding primitives to follow
On-chain, the applications are immediate. Smart contracts can already verify TDX quotes directly, which means you can build AI oracles: a model attests that it evaluated some real-world data and produced this judgment, and a contract acts on it. Autonomous agents can hold funds because the code controlling the keys is provably the code that was audited. Prediction markets, parametric insurance, content authenticity: anywhere the question "but who says the AI really said that?" currently kills the design, attestation answers it.
But blockchain examples are a limited, narrow version of this, because the same primitive matters anywhere two parties don't fully trust each other, which is to say everywhere:
Healthcare. Models over medical records, imaging, and genomics, with a hardware-backed guarantee that nothing is retained.
Neuroscience and biotech. Brain-computer interface streams, mental health transcripts, proprietary compound libraries: data that today cannot leave its owner's trust boundary at all.
Two-sided protection. The enclave hides the user's data from the model owner and the model's weights from the user and the host. "Bring your model to my data" without either side exposing anything.
Personal AI agents. Agents that read your email, calendar, and finances only make sense if the processing is provably confidential and ephemeral.
Identity. Our own case at Self: verification over biometrics and government documents, running in enclaves with measurements published on-chain and verification done by the client, in production today.
Where zero-knowledge proofs fit
There's a natural objection to the trust loop as described: it assumes the enclave code is open source. What if the code is your company's core asset?
Today's honest answer is that you should open-source the security-critical shell (the attestation handling, the key management, the I/O paths) and keep your secret sauce as data or weights loaded into it, which the TEE protects anyway. That covers most real cases.
The more interesting answer is coming. Zero-knowledge proofs let you prove properties of a computation without revealing the computation. Applied here: prove that a closed-source binary never writes its input to persistent storage, that its only output channel is the response socket, that it contains no code path that exfiltrates. The measurement in the attestation quote then refers to a binary you haven't published, accompanied by a ZK proof of exactly the properties users care about, with your proprietary techniques staying proprietary. Instead of reading the source, users check the proof.
Where things stand
A caveat: TEEs have had vulnerabilities, side channels get published, and microcode gets patched. The trust surface is small, public, and checkable, and that is enough to build on.
And building is the point. Attested inference turns whole categories of previously impossible products into engineering problems. The primitives are deployed, and the design space is mostly unexplored. At Self, we've spent years building at the edge of enclaves and zero-knowledge cryptography.
If you're working on inference, bio or neuro tech, or looking into private compute, reach out.
Published
Related blogs



Stay updated
Join us on the road to privacy-first identity.